Details
-
Type:
Improvement
-
Status: Closed (View Workflow)
-
Priority:
 Major
Major
-
Resolution: Done
-
Affects Version/s: None
-
Fix Version/s: 9.0.1 Minor Release
-
Labels:None
-
Story Points:3
-
Sprint:Fall 2017
Description
Currently, when a new track is added, a row is inserted in the data management table at some random position.
There is code for ordering the rows, but it is not implemented effectively.
Current task:
Fix the existing method to
a) make slightly more sense,
b) actually work
The position of a new track added to the table should be consistent and predictable.
This ordering is handled by featureTableComparator in DataManagementTableModel.java.
When datasets are initially passed to DataManagementTableModel functions, the datasets are ordered alphabetically. This order may is then lost when we pass it through a hash map in the function feature2StyleReference.
Ideally, the order would reflect the order in which tracks were added, but that is a larger scope and a separate issue (see related issues).
Attachments
Issue Links
- relates to
-
-
- To-Do
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Rank | Ranked higher |
| Summary | Make track order in Data Management Table same as main view | Make track order in Data Management Table logical |
| Description |
The order of tracks in the Data Management Table (top to bottom) should update whenever there is a change to the main view, so it always matches the order of tracks (top to bottom) in the main view.
Need to establish how to handle hidden tracks. |
Currently, when a new track is added, a row is inserted in the data management table at some random position. There is code for ordering the rows, but it is not implemented effectively. Current task: Fix the existing method to a) make slightly more sense, b) actually work The position of a new track added to the table should be consistent and predictable. Ideally, the order would reflect the order in which tracks were added, but that is a larger scope and a separate issue. |
| Description |
Currently, when a new track is added, a row is inserted in the data management table at some random position. There is code for ordering the rows, but it is not implemented effectively. Current task: Fix the existing method to a) make slightly more sense, b) actually work The position of a new track added to the table should be consistent and predictable. Ideally, the order would reflect the order in which tracks were added, but that is a larger scope and a separate issue. |
Currently, when a new track is added, a row is inserted in the data management table at some random position.
There is code for ordering the rows, but it is not implemented effectively. Current task: Fix the existing method to a) make slightly more sense, b) actually work The position of a new track added to the table should be consistent and predictable. This ordering is handled by featureTableComparator in DataManagementTableModel.java. When datasets are initially passed to DataManagementTableModel functions, the datasets are ordered alphabetically. This order may is then lost when we pass it through a hash map in the function feature2StyleReference. Ideally, the order would reflect the order in which tracks were added, but that is a larger scope and a separate issue (see related issues). |
| Sprint | Sprint 39 [ 47 ] |
| Rank | Ranked lower |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Status | In Progress [ 3 ] | Open [ 1 ] |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Attachment | Screen Shot 2017-04-20 at 12.59.39 PM.png [ 13958 ] |
{kind=link}
I submitted a pull request.
Ann reviewed it and asked for better comments in the code.
I added comments and I updated the pull request.
| Assignee | Ivory Clabaugh [ ieclabau ] | Ann Loraine [ aloraine ] |
| Status | In Progress [ 3 ] | Open [ 1 ] |
| Priority | Major [ 3 ] | Blocker [ 1 ] |
| Status | Open [ 1 ] | Pull Request Submitted [ 10101 ] |
| Story Points | 3 |
| Status | Pull Request Submitted [ 10101 ] | Needs Testing [ 10002 ] |
| Status | Needs Testing [ 10002 ] | Pull Request Submitted [ 10101 ] |
| Status | Pull Request Submitted [ 10101 ] | Reviewing Pull Request [ 10303 ] |
| Assignee | Ann Loraine [ aloraine ] | Ivory Clabaugh [ ieclabau ] |
| Assignee | Ivory Clabaugh [ ieclabau ] | Ann Loraine [ aloraine ] |
| Assignee | Ann Loraine [ aloraine ] | Ivory Clabaugh [ ieclabau ] |
| Assignee | Ivory Clabaugh [ ieclabau ] | Ann Loraine [ aloraine ] |
I made the change that Ann requested (variable name changed from newFeatures to theFeatures).
The branch has been updated and a pull request is waiting.
| Status | Reviewing Pull Request [ 10303 ] | Needs Testing [ 10002 ] |
Reminder: Wait until Jenkins builds the new installer before testing.
| Assignee | Ann Loraine [ aloraine ] | Mason Meyer [ mason ] |
| Priority | Blocker [ 1 ] | Major [ 3 ] |
| Status | Needs Testing [ 10002 ] | Testing In Progress [ 10003 ] |
My testing confirms that the Data Management table is now ordering tracks in the logical manner expected. Tracks are grouped with the folders they come from and the tracks are ordered alphabetically within that group. I found no ways to break this functionality and I did not notice any other side effects. Since this issue is resolved, it will now be closed.
| Resolution | Done [ 10000 ] | |
| Status | Testing In Progress [ 10003 ] | Closed [ 6 ] |
| Fix Version/s | 9.0.1 Minor Release [ 10500 ] |
| Workflow | Loraine Lab Workflow [ 17730 ] | Fall 2019 Workflow Update [ 19785 ] |
| Workflow | Fall 2019 Workflow Update [ 19785 ] | Revised Fall 2019 Workflow Update [ 21904 ] |
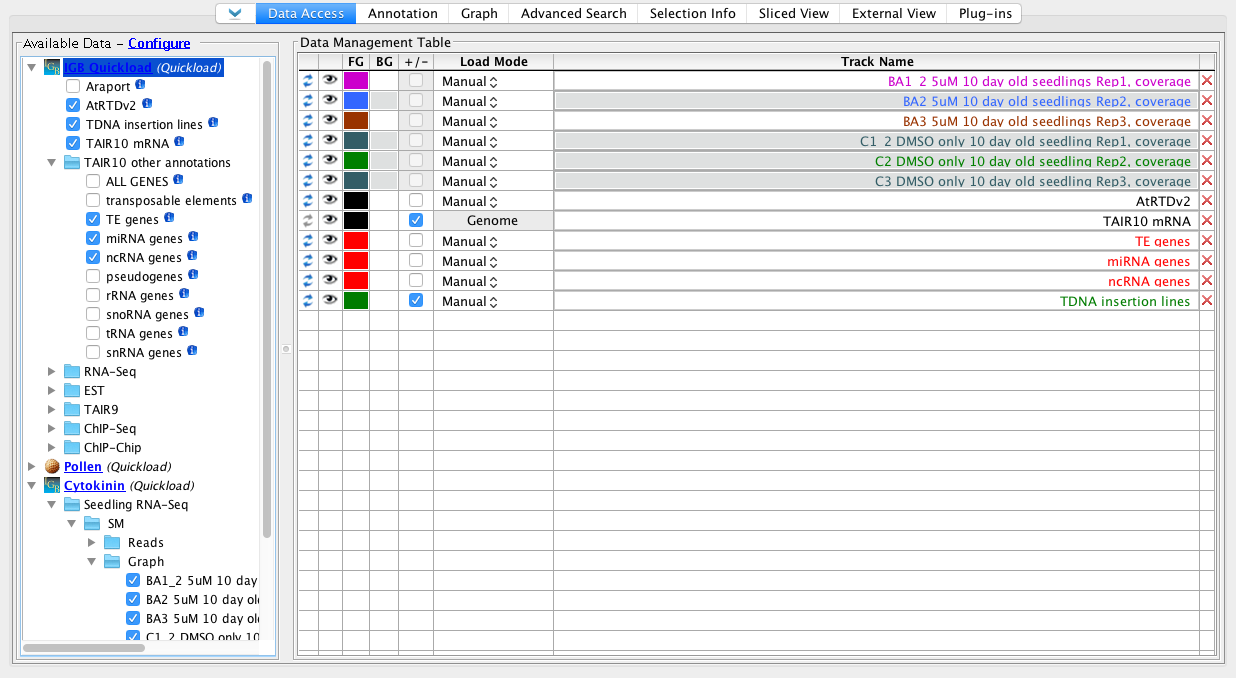
This is an example of the new row ordering.
Notice that the top several rows are features from the same group (same folder) and they are ordered alphabetically, which is immediately intuitive.
The lower rows are from the IGB Quickload set, and some are in a folder "TAIR 10 other annotations" which puts them together as a group in the middle of the other datasets from the same source.
This is not ideal. But it is better than the previous system which did not enforce any logical row ordering.