Details
-
Type:
Task
-
Status: Closed (View Workflow)
-
Priority:
 Major
Major
-
Resolution: Done
-
Affects Version/s: None
-
Fix Version/s: None
-
Labels:None
-
Story Points:1
-
Sprint:Spring 1 2022 Jan 3 - Jan 14, Spring 2 2022 Jan 18 - Jan 28
Description
Previous analysis of the RNA-Seq data found that the treatments triggered changes in expression and splicing. Since our first processing of the data, we added a new dataset in which a methylation inhibitor was applied, but this dataset has not been processed as yet.
A new RNA-Seq data analysis pipeline has been developed that uses the Nextflow workflow system, and we've been using this workflow system to process data from the pollen heat stress project. Also, this workflow management system is better equipped to accommodate diverse samples, e.g., sample libraries sequenced using different strategies (single- versus paired-end) and read lengths.
Since we need to process a new methylation-inhibitor RNA-Seq dataset and incorporate it into our analysis, let's reprocess the data using a more up-to-date workflow - the nc-core/rnaseq pipeline.
The first steps in doing this will be to:
- generate a comma-separated sample sheet data file that relates SRA run identifiers to experimental attributes, required for running nextflow. Note that we can also use the sample sheet as inputs for statistical analyses.
- generate a script that will download the SRA data files and convert them to fastq, required for running the pipeline. (Note: The project identifier is: PRJNA481973/)
The sample sheet data file columns will include the following fields:
- SRA run identifier (e.g, SRR7591232)
- fastq_1 - SRR name with _1 appended (e.g, SRR7591232_1)
- fastq_2 - SRR name with _2 appended, or blank for single-end samples ( (e.g, SRR7591232_2)
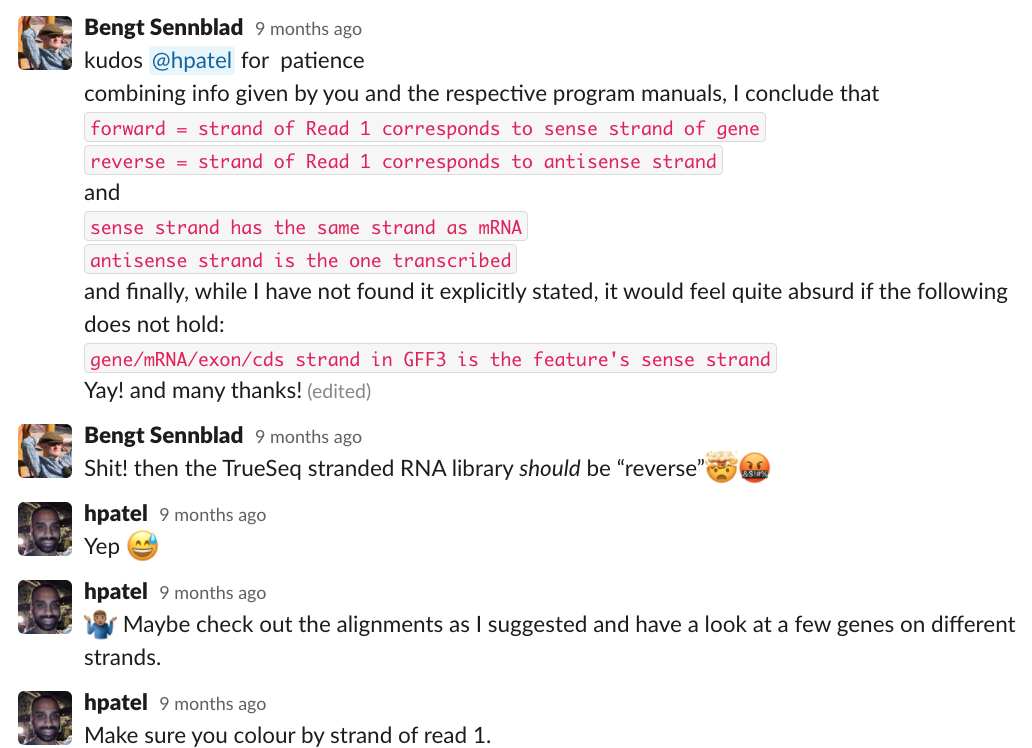
- strandedness - should be "reverse" for Truseq Illumina protocol (see attached image from nf-core/rnaseq slack)
- genotype - A (Agami), M (M103)
- treatment - C (control), E (salt)
- 5-Azacytidine treatment - Y (treated), N (not treated)
- tissue - S (shoot), R (root)
- replicate - 1, 2, 3
- read length