Details
-
Type:
Task
-
Status: Closed (View Workflow)
-
Priority:
 Major
Major
-
Resolution: Done
-
Affects Version/s: None
-
Fix Version/s: None
-
Labels:None
-
Story Points:0.5
-
Epic Link:
-
Sprint:Spring 2 2023 Jan 16
Description
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq
This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline.
Kindly run the nf-core pipeline in this location:
- /nobackup/tomato_genome/mark-2022-timeseries
Note on attached files:
- multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html
- Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK
- 2023-01-18_timeseries_multiqc_report.html - MultiQC report from re-running nextflow (Molly's new work)\
- sample.csv - new samples file used to re-run nextflow (Molly's new work)
Attachments
Issue Links
Activity
| Field | Original Value | New Value |
|---|---|---|
| Epic Link | IGBF-2993 [ 21429 ] |
| Assignee | Ann Loraine [ aloraine ] |
| Summary | Re-run nfcore rnaseq pipeline for seedlingPollen data | Run nfcore rnaseq pipeline for time course data |
| Description | We need to re-run nf-core pipeline with a new strandedness parameter as noted in attached multiqc report. |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries |
| Summary | Run nfcore rnaseq pipeline for time course data | Run rnaseq pipeline on |
| Summary | Run rnaseq pipeline on | Run rnaseq pipeline on mark-2022-timeseries |
| Attachment | 2022-11-24_multiqc_report.html [ 17651 ] |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries Note on attachments: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries Note on attachments: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: / * nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
| Assignee | Molly Davis [ molly ] |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html * Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK |
| Attachment | sample.csv [ 17652 ] |
| Status | To-Do [ 10305 ] | In Progress [ 3 ] |
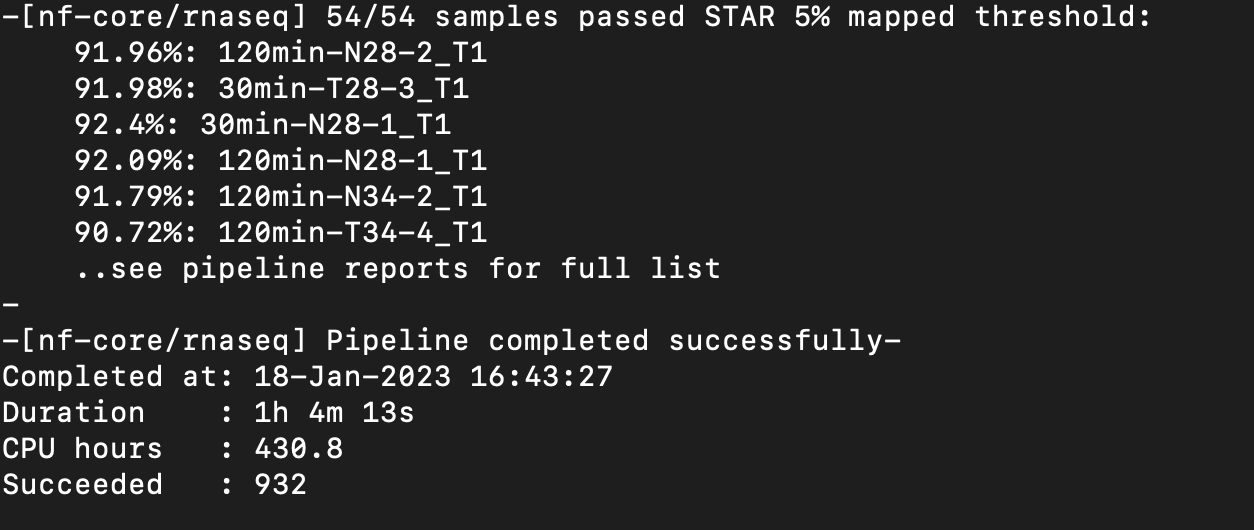
| Attachment | Screen Shot 2023-01-18 at 4.45.24 PM.png [ 17654 ] |
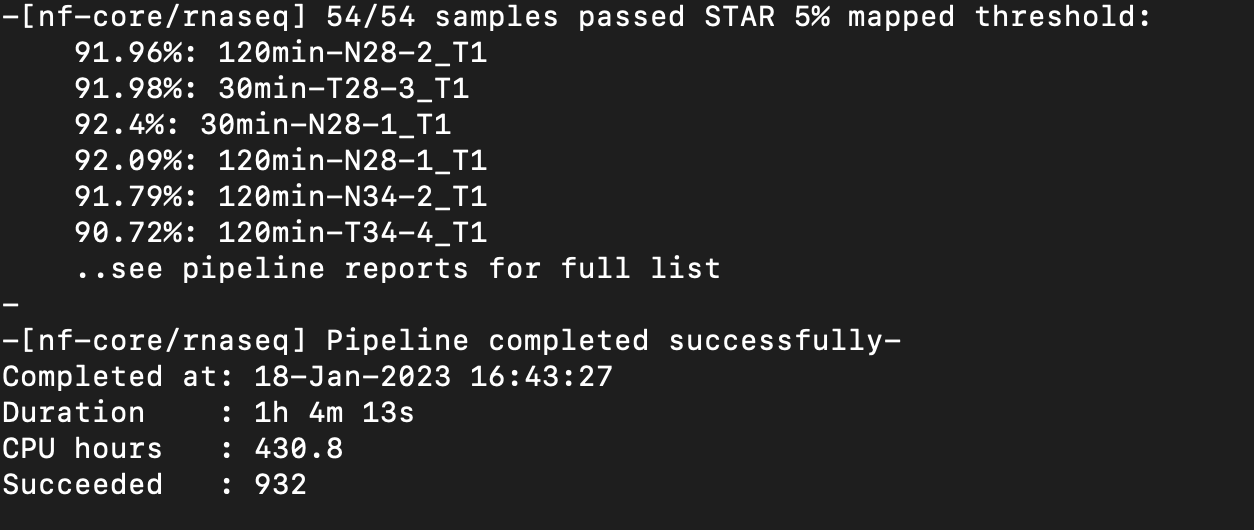{kind=link}
| Assignee | Molly Davis [ molly ] |
| Status | In Progress [ 3 ] | Needs 1st Level Review [ 10005 ] |
| Attachment | timeseries_multiqc_report.html [ 17658 ] |
| Assignee | Ann Loraine [ aloraine ] |
| Status | Needs 1st Level Review [ 10005 ] | First Level Review in Progress [ 10301 ] |
| Status | First Level Review in Progress [ 10301 ] | Needs 1st Level Review [ 10005 ] |
| Status | Needs 1st Level Review [ 10005 ] | First Level Review in Progress [ 10301 ] |
| Status | First Level Review in Progress [ 10301 ] | Ready for Pull Request [ 10304 ] |
| Status | Ready for Pull Request [ 10304 ] | Pull Request Submitted [ 10101 ] |
| Status | Pull Request Submitted [ 10101 ] | Reviewing Pull Request [ 10303 ] |
| Status | Reviewing Pull Request [ 10303 ] | Merged Needs Testing [ 10002 ] |
| Status | Merged Needs Testing [ 10002 ] | Post-merge Testing In Progress [ 10003 ] |
| Resolution | Done [ 10000 ] | |
| Status | Post-merge Testing In Progress [ 10003 ] | Closed [ 6 ] |
| Assignee | Ann Loraine [ aloraine ] | Molly Davis [ molly ] |
| Attachment | timeseries_multiqc_report.html [ 17658 ] |
| Attachment | 2023-01-18_timeseries_multiqc_report.html [ 17667 ] |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html * Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html * Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK * 2023-01-18_timeseries_multiqc_report.html - MultiQC report from re-running nextflow (Molly's new work) |
| Description |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html * Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK * 2023-01-18_timeseries_multiqc_report.html - MultiQC report from re-running nextflow (Molly's new work) |
Run nextflow for the dataset in:
/projects/tomato_genome/rnaseq/mark-2022-timeseries/30-771363348/00_fastq This is the "time course" dataset discussed by Rasha at the 2023-01-17 group meeting. Note that she has already run nextflow for this dataset but using "unstranded" for the "strandedness" parameter in the "samples.csv" file. It turns out this dataset comes from libraries that were created using a strand-specific RNA-Seq library. To be on the safe side, we should re-run the pipeline using parameter "reverse", as indicated in the multiQC report included with Rasha's initial run of the nextflow nf-core rnaseq pipeline. Kindly run the nf-core pipeline in this location: * /nobackup/tomato_genome/mark-2022-timeseries Note on attached files: * multiqc report on the entire run done by Rasha is attached, copied from google drive location GTTR-NSF PGRP - 2020-24 IOS-1939255 > Experiments > Rasha_RNA-seq_Time_Course > Results > multiqc > star_salmon > multiqc_report.html * Link: https://drive.google.com/drive/u/1/folders/1GJnZefP-7TE-ch-c0lblGZMOqpwSgZRK * 2023-01-18_timeseries_multiqc_report.html - MultiQC report from re-running nextflow (Molly's new work)\ * sample.csv - new samples file used to re-run nextflow (Molly's new work) |