Details
-
Type:
Task
-
Status: Closed (View Workflow)
-
Priority:
 Major
Major
-
Resolution: Done
-
Affects Version/s: None
-
Fix Version/s: None
-
Labels:None
-
Story Points:1
-
Epic Link:
-
Sprint:Spring 1
Description
Investigate UCSC's GenArk system (https://api.genome.ucsc.edu/list/genarkGenomes) and check whether it can be integrated into IGB.
Attachments
Activity
Investigated how the annots.xml is generated, there are two files involved in it, the 2bit file and the trackDb file, the bit file is not involved in the datasets or tracks extraction, if it's present it's just added into the annots.xml file, the tracks are taken from the trackDb file. The reason the folder structure looks like the below is that the title that is being used for the track name is coded like this:
filesChild.setAttribute('title', (trackName + "/" + type + "/" + shortLabel).replace(" ", "_"))
Looked into the Trackhub code (https://bitbucket.org/lorainelab/hub-facade/src/main/) and how it's being added to IGB a little bit to better understand it. Found the below things: The file that's responsible for converting the hubUrl files content to IGB compatible content is https://bitbucket.org/lorainelab/hub-facade/src/main/igb_trackhub/api/create_resources.py and Nowlan Freese the reason why the name is populated from the organism field instead of the scientific name is that we are using this API (https://api.genome.ucsc.edu/list/hubGenomes?hubUrl=https://hgdownload.soe.ucsc.edu/hubs/GCA/000/001/905/GCA_000001905.1/hub.txt) to get the info of the hub genomes instead of reading it from the hub.txt directly, this one is provided by UCSC which gives the info in JSON format, i believe that's the reason we are using that and this API is not returning the scientific name it only has the organism field. And as to why we have that folder structure, I still have to look into it but we are generating the annot.xml file, which is used in the Quickload code to load the dataset, by using the 2bit file that's present in the response of the above API.
Link to Track Hub converter epic: https://jira.bioviz.org/browse/IGBF-2831
This might be helpful: BookmarkHttpRequestHandler.java
Website to convert trackhubs to IGB Quickloads: https://translate.bioviz.org/
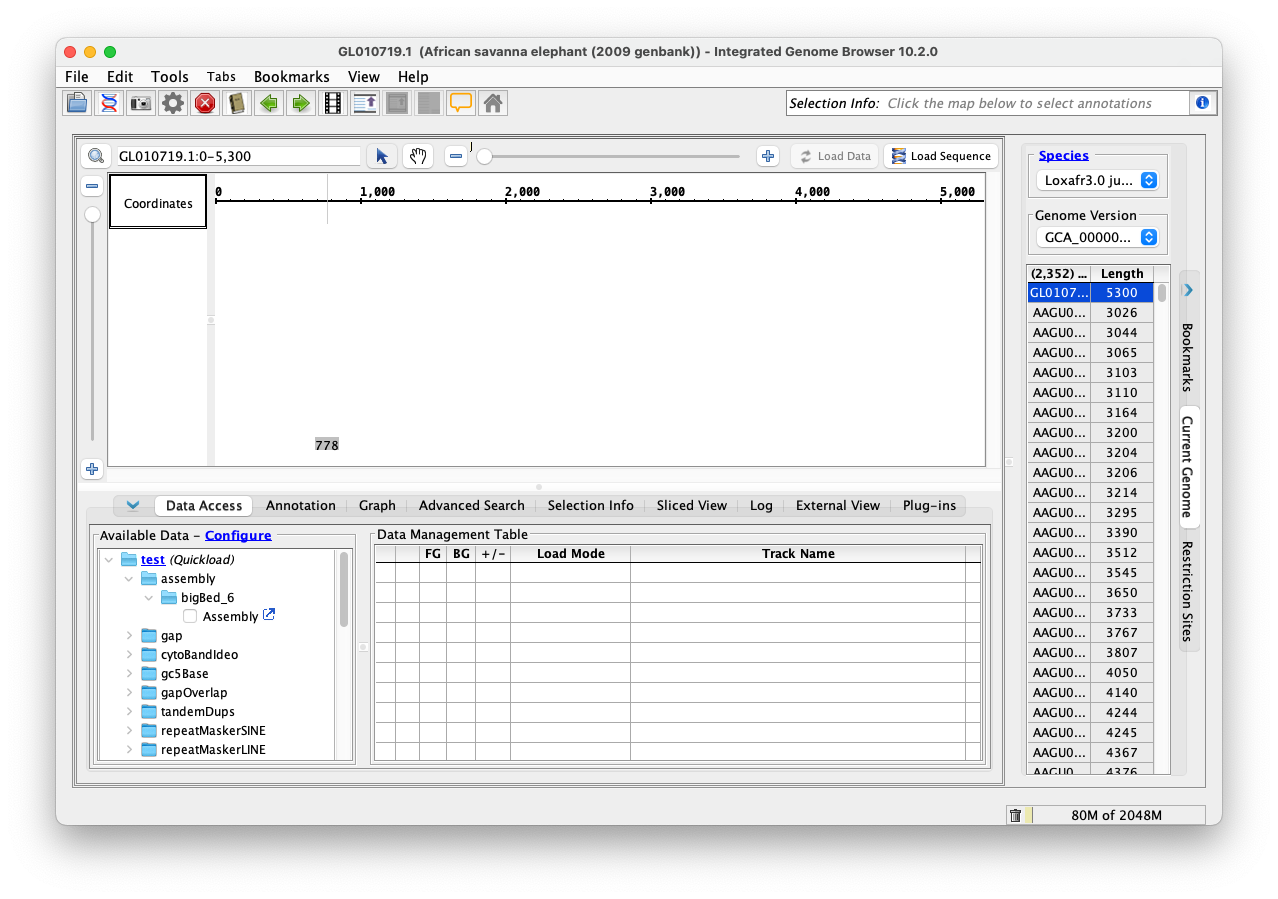
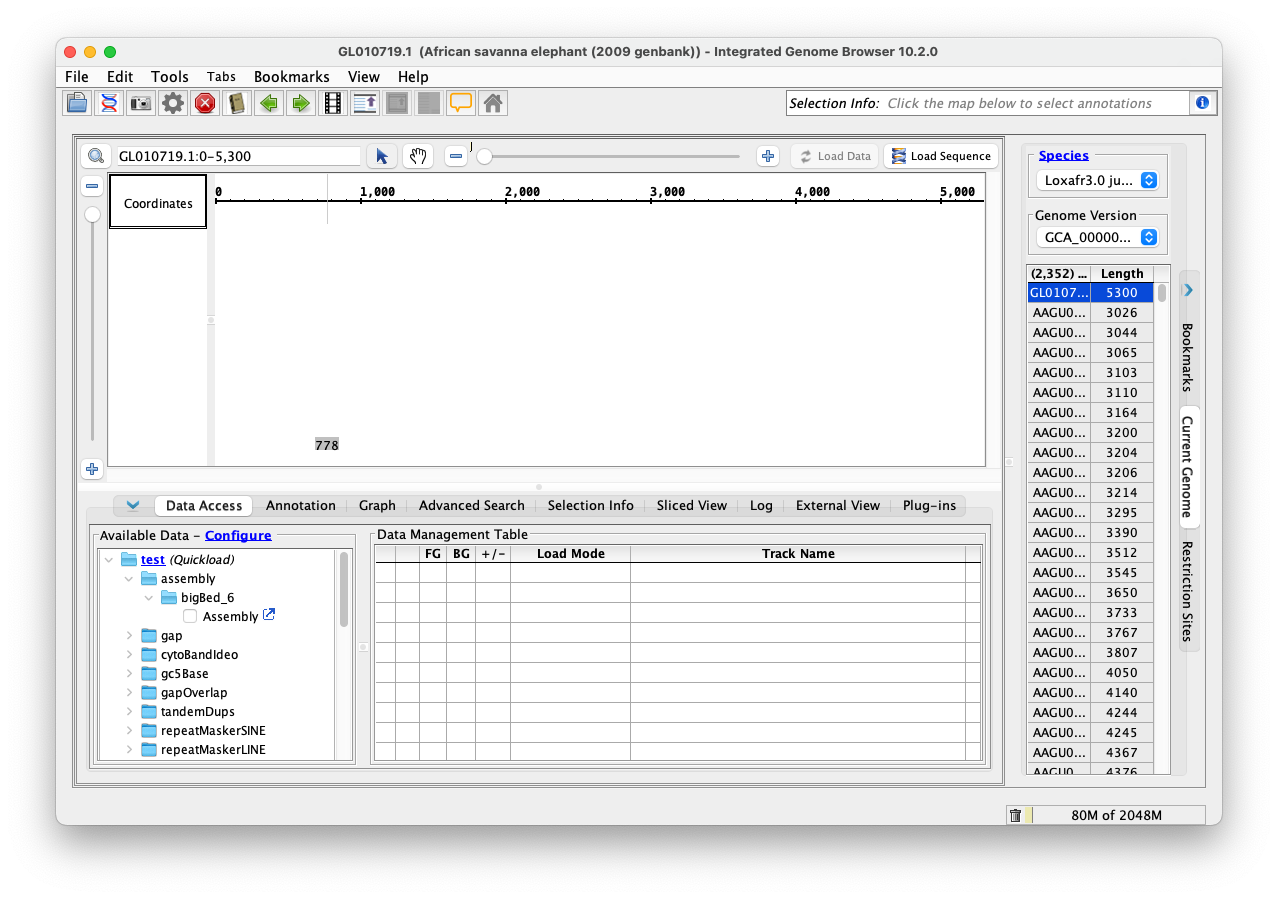
Investigated the genomes and tracks all the APIs work similar to the UCSC genomes and on top of it we can directly get the bigbed file from the hub URLs that are provided in the API response which will decrease a lot of API calls and as far as I checked all genomes in this GenArk seem to have the hubUrl, the hub page for that genome (eg: https://hgdownload.soe.ucsc.edu/hubs/GCA/000/001/905/GCA_000001905.1/) and the bigDataUrl, where the actual annotation file exists (eg: https://hgdownload.soe.ucsc.edu/hubs/GCA/000/001/905/GCA_000001905.1/bbi/GCA_000001905.1_Loxafr3.0.ncbiRefSeq.bb). Initially we can get the genomes and tracks from the API call and we can use this file to load the data into IGB for a particular track, instead of making multiple API calls and we already have a .bb file parser. So, implementation can be done and it should be easier too.
Tracks API for the selected genome: https://api.genome.ucsc.edu/list/tracks?genome=GCA_000001905.1
Things we need to check before implementing:
- The chromosomes seem a bit odd to me, we have to verify whether the chromosome data is correct or not. You can check it by either using this API call: https://api.genome.ucsc.edu/list/chromosomes?genome=GCA_000001905.1 or by loading the above bb file into IGB.
- Also, when the data is loaded to IGB, it seems to show only one transcript per chromosome, we have to verify that as well.
- Finally, have to check what file types we can or want to support and verify whether the existing logic to parse these files is correct or not.
Nowlan Freese We can discuss these points and decide on how to move forward.
Closing this ticket as the investigation for this ticket scope is done and will investigate different approaches like directly using the translate.bioviz.org code to add the Quickload or using a custom one to add the Quickload in this ticket: https://jira.bioviz.org/browse/IGBF-4087